Scope
The goal of eventutilities-python is to provide helpers and APIs that abstract away the complexity
of Flink and Wikimedia’s own stream management and SerDe.
Use cases
Python services should be simple stateless pipelines that::
Listen to existing Kafka topic
Make a call to third party systems (e.g. MW Action API)
Produce some output that combines the data
Emits error events to a side output kafka topic
Provides the ability to backfill and/or bootstrap from events outside of kafka
We often refer to this type of application as ones that follow an**enrichment pattern. Current use cases can be found on Wikitech.
Architecture & APIs
This section describes the architecture and API of https://gitlab.wikimedia.org/repos/data-engineering/eventutilities-python, a python module for writing simple Python event processing services.
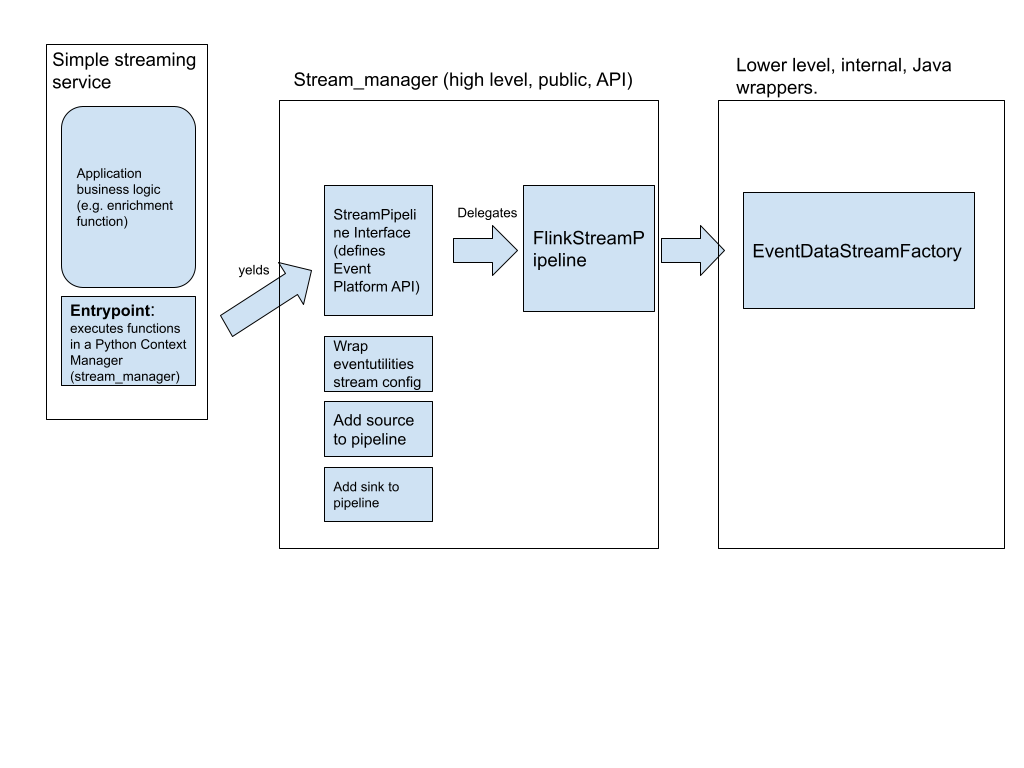
Stream context manager
Developers will interact with Event Platform via the stream_manager context manager:
with stream_manager(source=SourceDescriptor(...), sink=SinkDescriptor(...)) as stream:
…
Where SourceDescriptor and SinkDescriptor are config boilerplate that encode the source/sink connection type (kafka, file)
and a fully qualified, versioned, stream name as <stream name>:<version>
sink must specify the stream version. Producer code (which is usually why someone is writing one of these pipelines) implicitly knows the schema that they will produce, as they are setting the fields in the dict.
Sources however are multi-purpose, and many consumers can use them. Consumers almost always want the latest schema, and as long as schemas are backwards compatible, their code won’t care about the version. Fields added in a newer schema will not be used or referenced by older consumer code.
To enforce conventions in production environments, stream_manage requires both source and destination schemas to be versioned. Internal classes might relax this condition and offer more flexibility.
Eventutilities-python provides a context manager (stream_manager) that encapsulates logic for:
Setting up a Flink Streaming Context
Resolving stream configuration and schema management via Wikimedia’s stream config API.
Defining Source and Sink
Setting up an Error stream
StreamManager interface
stream_manager yields an object that implements the following interfaces.
class Stream(ABC):
"""
Stream is an interface that implies operations on a datastream.
It defines the API contract with users of eventutilities-python.
"""
@abstractmethod
def filter(self, func: Callable[[Any], Any], name: Optional[str] = None) -> Any:
pass
@abstractmethod
def partition_by(self, func: Callable[[Any], Any]) -> Any:
pass
@abstractmethod
def process(self, func: Callable[[Any], Any], name: Optional[str] = None) -> Any:
pass
@abstractmethod
def execute(self) -> Any:
pass
It exposes a lazily-evaluated data stream by means of operations that can be performed on it:
filter(): applies a filter function (e.g. remove canary events). This is useful for data clean up and pre/post processing.process(): Applies a map function with metrics and error handling to a stream.parition_by()partition a stream by key.execute(): streams are lazily evaluated. A call to execute() will trigger execution.
Event processing function
Business logic should be implemented in a process function with the following signature:
def my_process_function(input_event: dict) -> dict:
output_event : dict = {}
# process input and shape it into output
return output_event
The function is dispatched to a Flink cluster by an implementation of Stream.process() method.
Key requirements:
The function should be serializable.
The function should accept Python
dicts and return Pythondicts.Errors are logged and forwarded to a sideoutput error topic.
Input and output dictionaries should conform to valid event platform json schemas (e.g. Events). None values are considered an error, and emit them to the logger sideoutput
Error reporting
Application errors should be reported to a Flink SideOutput that produces events compliant with the general purpose error schema for error side outputs. The event that caused the error can be included as a raw json string in this error event.
EventDataStreamFactory
EventDataStreamFactory is a helper class responsible for instantiating Flink DataStream via factory methods.
It wraps capability of the homonymous Java class, but right now does not provide full Java methods semantics. Key functionality:
Init a EventDataStream factory, that interops with EventStreamConfig and JSon SerDe and validators
Wrap methods for reading data from Json line files, used in tests and local development.
Provide a converter for EventRowTypeInfo to RowTypeInfo and to/from Python
dicts.
Asynchronous HTTP callback via DataStream minibatching.
Since pyflink does not currently support the Async I/O DataStream interface (slated to be done in Flink 1.18) we have been
experimenting with a mini batching approach where events are processed concurrently with
a thread pool local to an operator (KeyedProcessFunction).
API Changes
The following APIs have been changed:
Introduce a
partition_by()public method to stream manager. We can’t make too many assumptions on stream payload, and should delegate partitioning to users needing to invokeprocess()s.Add a local thread pool and a “count with timeout” windowing trigger to
EventProcessFunction. Closures passed toprocess()will be executed in the threadpool. This approach allows for async operations, and at the same time reduces memory footprint generated by having too many open mini-batching windows.
We opted to introduce a partition_by() instead of passing keys to process() for two reason:
we want to be explicit about what is going on and keep the
process()logic simple (there’s already more coupling with the count+trigger logic than I’d like).we must be mindful that this is a workaround, and we eventually want to adopt async DataStreams once they land upstream. We should then be able to drop
partition_by()(while being backward compatible with existing codebases) without having to alter theprocess()contract.
How mini-batching works
A data stream is minibatch by using a windowing function and an operator that consumes all elements of the window and yields back an arbitrary number of records. An example isProcessWindowFunction.
datastream = (
datastream.key_by(lambda row: row["wiki_id"])
.window(TumblingProcessingTimeWindows.of(Time.seconds(window_size)))
Two design choices we considered:
Should we use window keyed or non-keyed windows. Currently we don’t really make use of task parallelism, but this might change in the future. Depending on the partition keys we select, we might end up with data skew. Currently eventgate keys by (wiki_id, page_id), should we adopt the same strategy?
Whether we should batch based on time or record counts. The former approach is straightforward to implement, and resilient to data skew. The latter would lead to a more uniform distribution of events, but might result in a low cardinality partition to starve. Would it make sense to try and combine both approaches?
We settled on using a key datastream and an ad hoc KeyedProcessFunction that combines count and time based triggers.
Experiments showed that this approach decreased memory pressure on the beam executor,
by reducing the number of windows spawned and kept open in the worker processing queue.
Count + time window should also be better for lower volume streams, as the time trigger will happen if the window doesn’t fill soon enough.
Event processing function
We introduced an EventProcessFunction class that:
Calls a user provided function, expected to take a single event dict, and return a transformed event dict.
Implements a thread pool on a minibatch to allow asynchronous function execution. A batch is considered full when one the following conditions are met: 1.
batch_sizeelements have been consumed. 2 . and intervalbatch_duration_msmilliseconds have elapsed. Mini batching with count and time triggers combines two KeyedProcessFunction methods to mini-batch a datastream using windows:process_elements()consumes incoming records, and submits futures to an executor thread pool. Oncebatch_sizerecords have been consumed, futures are collected and the current window is closed. Whenprocess_elements()is invoked and no future has been scheduled a timer is registered in Flink Timer Registry. The timer will trigger at <current_time> +batch_duration_ms.on_timer()is triggered when the window timeout is reached and the timer registered inprocess_elements()fires. Any pending future is collected and the current window is closed. TODO: we should consider extracting this logic out of a Process function and move it to a trigger. Currently there is tight coupling with async execution and our EventProcessFunction logic, since it is our public API and we don’t need users to be concerned with partitioning and managing windows. Future use cases could benefit from a reusable trigger. Maybe part of the Java codebase?
Emits various Flink metrics about memory used, and process func results.
Event Process Function decoratorsg
The functions module provides decorator for ad-hoc processing use cases:
http_process_functionthat wraps a function and handles instantiation of arequests.Sessionobject, with a retry policy and a worker pool.